BearcatCTF Pipeline Deep Dive (v1.5.0)
This document is a breakdown of the BearcatCTF deployment pipeline. It details the exact sequence of jobs, variable routing, and state management across both the Challenges and Infrastructure repositories to help maintainers debug and update the deployment lifecycle.

BearcatCTF Challenges Pipeline
This section breaks down the internal logic of the BearcatCTF-Challenges repository pipeline. This pipeline acts as the compiler for our challenges. Its primary job is to validate challenge configurations, build the Docker images, package the automated solve scripts, and stage everything for the infrastructure deployment.
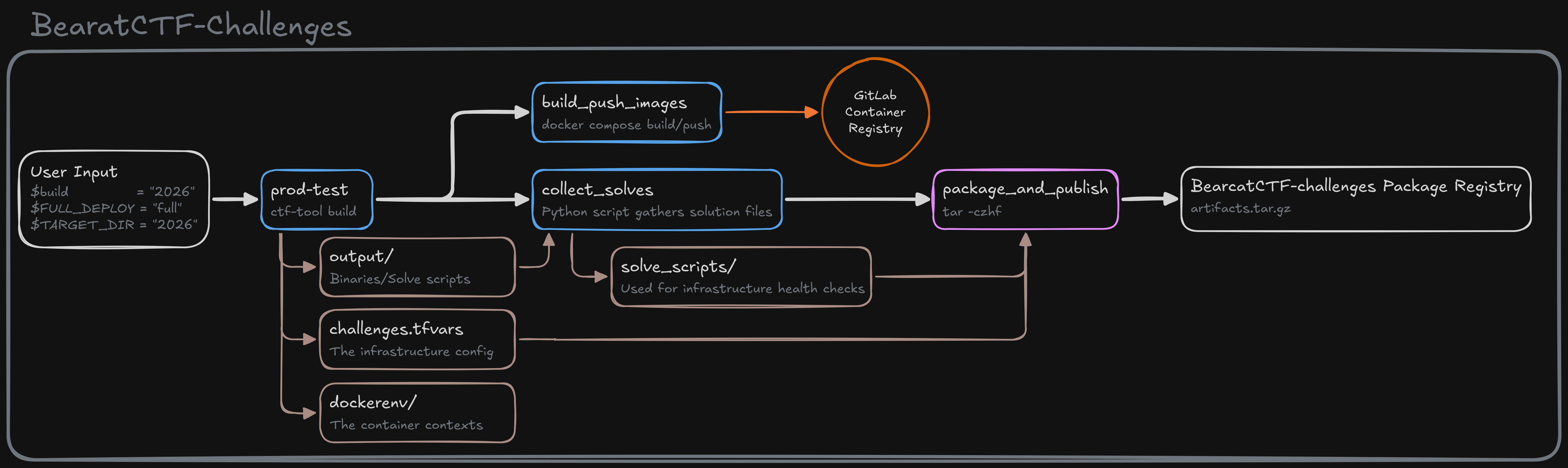
1. Pipeline Controls & Variables
Before looking at the jobs, it is critical to understand the variables that control the pipeline's execution. These act as safety rails to prevent accidental production deployments.
TARGET_DIR(e.g., "2026"): Tells the pipeline which folder to scan. Because we keep old challenges in the repo, this makes sure we only build and deploy the current year's challenges.build: A manual toggle. If set to"false", the heavybuild_push_imagesjob is completely skipped. If set to the current year (e.g.,"2026"), it authorizes the pipeline to compile and push Docker containers to the registry.DEPLOY_TARGET: Controls the downstream blast radius."none": Stops after validation. Does not trigger the infra pipeline."ctfd": Triggers the infra pipeline, but purposely blanks out thechallenges.tfvarsfile first. This bypasses AWS resource creation and only updates the scoreboard text/files."full": Authorizes a complete AWS infrastructure deployment.
This is made possible by using defined Gitlab CI/CD rules to define what and how the jobs execute depending on the provided variables.
2. Stage: Test & Validate
dev-test & prod-test
These jobs use the custom ctf-tool Docker image to parse all the challenge.yaml files inside the TARGET_DIR.
- The Mechanism: The tool validates the YAML syntax, confirms flags exist, and compiles the raw configurations into machine-readable infrastructure files.
- Artifact Generation (The Outbound Arrows): The
prod-testjob is the foundational root of the entire visual flowchart. When it succeeds, it outputs three critical artifacts:output/: Contains any static binaries or files meant for players to download.dockerenv/: A sanitized directory containing theDockerfileand source code, prepped specifically for the Docker daemon to build.challenges.tfvars: The master configuration file that Terraform will eventually use to provision AWS resources.
3. Stage: Build
build_push_images
This job is responsible for compiling the dynamic challenge backends and securely storing them. It utilizes a Docker-in-Docker (dind) environment on the Gitlab runner.
- The Arrow (
prod-test->build_push_images): This job strictlyneedstheprod-testjob. Why? Because it requires thedockerenv/artifact. - The Destination: It authenticates using Gitlab CI variables and pushes the compiled images directly to the Gitlab Container Registry.
4. Stage: Full Pipeline (Packaging & Handoff)
This stage gathers all the separate pieces generated in the previous steps and bundles them into a single package.
collect_solves (The Python Script)
AWS Lambda needs our health check scripts, but having fifty files all named solve.py is a logistical nightmare. This job runs a custom Python script to cleanly aggregate them.
- How it works:
- It recursively scans the
TARGET_DIRfor any file namedsolve.py. - The Filter: It explicitly skips files inside
output/orbuild/directories. More importantly, it checks if aDockerfileexists in the same folder. If there is noDockerfile, it skips the script. Why? Because static challenges don't get deployed to AWS EC2s, meaning they don't need Lambda health checks. - Collision Handling: It takes the parent directory's name, converts it to lowercase with underscores, and renames the script (e.g.,
solve.pybecomessql_injection.py). If two challenges have the same parent folder name, it appends a numerical counter to prevent overwriting.
- It recursively scans the
- The Output: It drops all the cleanly named scripts into a
solve_scripts/artifact directory.
package_and_publish (The Funnel)
This job acts as the central funnel of the flowchart, merging artifacts from two parallel tracks.
- The Converging Arrows:
- Arrow 1 (
collect_solves->package_and_publish): It waits for the Python script to finish generating thesolve_scripts/directory. - Arrow 2 (
prod-test->package_and_publish): It waits to inherit thechallenges.tfvarsfile generated way back in the testing stage.
- Arrow 1 (
- The Mechanism: Using Alpine Linux, it runs a
tar -czhf artifacts.tar.gzcommand to compress the solve scripts and the.tfvarsfile together. - The Destination: It uses a curl API call to upload this single
.tar.gzfile to the BearcatCTF-challenges Package Registry.
infra_deploy (The Downstream Trigger)
This is the final job in the repository. It does not build or package anything. It basically acts as a webhook.
- The Arrow (
package_and_publish->infra_deploy): This job must wait for the package to successfully upload to the registry. - The Mechanism: Once the upload is confirmed, it uses the
trigger:keyword to wake up thebearcatctf-infrarepository. It passes along environment variables (UPSTREAM_VERSION,TARGET_DIR) so the infrastructure repo knows exactly whichartifacts.tar.gzpackage to download and deploy to AWS.
BearcatCTF Infrastructure Pipeline
This document breaks down the internal logic of the BearcatCTF-Infra repository pipeline. While the upstream Challenges pipeline acts as a compiler, this pipeline acts as the provisioner. It is responsible for securely authenticating with AWS, managing OpenTofu (Terraform) state, building Lambda dependencies, and dynamically provisioning cloud resources based on the incoming challenge configurations.
1. Pipeline Controls & State Management
Infrastructure as Code (IaC) is highly dependent on State. If the state file gets corrupted or overwritten, the cloud infrastructure becomes orphaned.
The workflow: Rules & DYNAMIC_STATE_NAME
Instead of using a single hardcoded state file, this pipeline dynamically alters its target state based on the branch or trigger source:
- Main Branch / Prod Trigger: Uses production as the state name.
- Merge Requests: Uses the branch name (e.g., feature/new-chals) as the state name. This creates an isolated sandbox environment that will not accidentally overwrite live production data.
The OpenTofu Component
To standardize deployments, we use the official Gitlab OpenTofu component. This abstracts away the raw tofu init / tofu plan commands and automatically configures Gitlab as the HTTP backend for our state files. It injects the fmt, plan, apply, and destroy jobs into our pipeline.
2. Stage: Pre-Run (Fetching & Setup)
Before OpenTofu can map out the infrastructure, it needs the blueprint.
fetch-artifacts
This job bridges the gap between the Challenges repository and the Infra repository.
- The Mechanism:
- If triggered by the upstream pipeline: It runs
scripts/fetch_upstream.pyto download theartifacts.tar.gzpackage (containing.tfvarsandsolve_scripts/). - If run manually by a developer locally: It prevents accidental production deploys by copying local
.devfiles (challenges.tfvars.dev) instead, and intentionally fails if production files are present.
- If triggered by the upstream pipeline: It runs
- The Blueprint: The
challenges.tfvarsfile output by this step is the master list for OpenTofu. For example, it tells OpenTofu that the challengepyfactorialneeds to run imagebroken_pyfactorial_challenge:lateston port59065and use thepyfacthealth check script.
Why Have It This Way?
By having two separate mechanisms it allows us to limit the scope when testing. For instance when working stricly on the Terraform code in the BearcatCTF Infra repository, we do not want to have to wait for the entire pipelne to finish. By creating two mechanisms that are triggered depending on the environment it allows us to have faster iterations when working on specific parts of the project.
The Hidden Setup Jobs (.authenticate & .prepare-plan)
These "dot" jobs don't appear directly in the visual graph as standalone boxes; they are injected into the OpenTofu jobs.
.authenticate: Eliminates static AWS passwords. It uses theGITLAB_OIDC_TOKENto assume a temporary AWS IAM role (aws sts assume-role-with-web-identity), grabbing credentials that expire in 1 hour..build-solve-scripts: AWS Lambda health checks need external Python libraries to solve challenges. This script installsrequests,pwntools, andpycryptodomeinto the localsolve_scripts/directory, drops in thectf_lib.pyhelper, and compresses it all intosolve_scripts.zip.
3. Stage: Dev Deployments (Merge Requests)
When a developer opens a Merge Request in the infrastructure repo, we want to test those changes safely in an ephemeral "review" environment.
dev-plan
- The Arrow (
fetch-artifacts->dev-plan): This job strictly needs the artifacts fetched in the pre-run stage to calculate what needs to change. - The Mechanism: It executes a speculative
tofu planagainst the dynamic branch state. - The Output: It generates a
plan.cacheartifact and thesolve_scripts.zipbundle.
dev-apply
- The Arrows (
fetch-artifacts,dev-plan->dev-apply): It needs the original source variables and the exactplan.cachefile to execute the deployment. - The Mechanism (Manual Gate): This job will not run automatically. A maintainer must click "Play". Once clicked, it provisions the temporary AWS resources and ties them to a dynamic Gitlab environment URL (
review/branch-name). - The Link (
on_stop): It sets anauto_stop_in: 2 hourtimer and links directly to the destroy job.
dev-destroy (The Gatekeeper)
- The Arrows (
fetch-artifacts,dev-plan,dev-apply->dev-destroy): It needs the state and cache of every previous step to safely tear down what was built. - The Mechanism: This job is set to
allow_failure: false. This is a strict security feature. If a developer applies a dev environment, Gitlab will completely block them from merging their Merge Request until they manually run this destroy job. This guarantees no rogue AWS resources are left running to rack up a massive bill.
4. Stage: Prod Deployments (Main Branch)
This track is the real deal. It only runs on the main branch or when triggered by a full deployment from the Challenges repo.
prod-plan
- The Arrow (
fetch-artifacts->prod-plan): Just like dev, it waits for thechallenges.tfvarsfile. - The Mechanism: Uses the
productionstate file. It compares the current live AWS environment against the incoming challenge packages and outputs aplan.cachedetailing exactly what EC2 instances, Load Balancers, or Lambda functions will be modified.
prod-apply
- The Arrows (
fetch-artifacts,prod-plan->prod-apply): Waits for the execution plan cache. - The Mechanism: This is a manual safeguard. Even during an automated upstream trigger, this job pauses. An infrastructure lead must review the Terraform plan and physically click "Play" to authorize the changes to the live environment.
prod-destroy
- The Arrows (
fetch-artifacts,prod-plan,prod-apply->prod-destroy): Inherits all previous state context. - The Mechanism: This is a manual job meant to be clicked when the CTF event is officially over, or if a critical infrastructure rollback requires deleting the entire production environment.